Reading csv file with multiple delimiters in pandas

Introduction
This is a memorandum about reading a csv file with read_csv of Python pandas with multiple delimiters.
specifying the delimiter using sep (or delimiter) with stuffing these delimiters into “[]”
So I’ll try it right away.
Details
Suppose I have the following csv file (tempo.csv) and I want to read it as separated with some delimiters (the right side of the time has a tab).
s1,s2;s3,datetime f1,f2,f3 a,b;c,2020/07/27 03:00 1.2,3.4,5.6 d,e;f,2021/09/28 13:03 2.3,4.5,6.7 g,h;i,2022/11/29 23:45 3.4,5.6,7.8
Here, let’s use the following seven types of delimiters to separate them.
“,” “;” “/” ” ” (space) “:” “t”(tab) “.”
How to specify the delimiter with sep (or delimiter) is just writing multiple delimiters in [] like this.
sep = “[]”
And specify engine =’python’ together.
# import pandas
import pandas as pd
#specifying the delimiter with sep (or delimiter), put multiple delimiters into "[ ]" .
#and specify engine ='python'
df = pd.read_csv("tempo.csv", sep = "[,;/ :t.]", engine='python')
df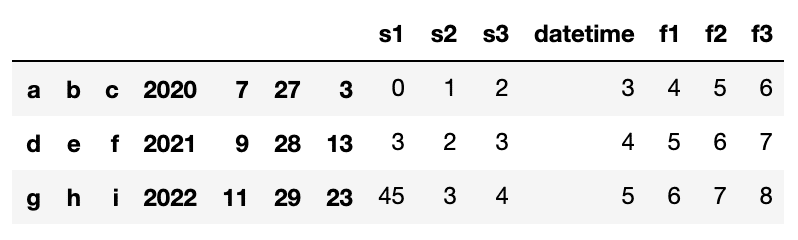
Done!
By the way, if you read a file without specifying anything, the default delimiter will be
“,”
Therefore
# import pandas
import pandas as pd
#default delimiter is ","
df = pd.read_csv("tempo.csv")
df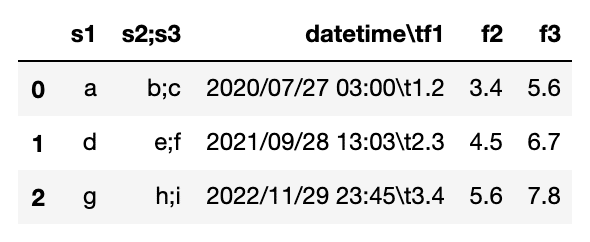
It will be like above.
And more;reorder header
You may already know by now… Reading a csv file as divided by multiple delimiters, the column header will be shifted and indexed weirdly….
So, replace the header with a list of column names according to the newly generated columns.
# import pandas
import pandas as pd
#Create a list of colmumn names in advance
cols = ["s1","s2","s3","year","month","day","h","m","f1-1","f1-2","f2-1","f2-2","f3-1","f3-2"]
#Specify the list of column names as "names"
df = pd.read_csv("tempo.csv", sep = "[,;/ :t.]", engine='python', names = cols)
#drop original header
df.drop(df.index[0], inplace = True)
df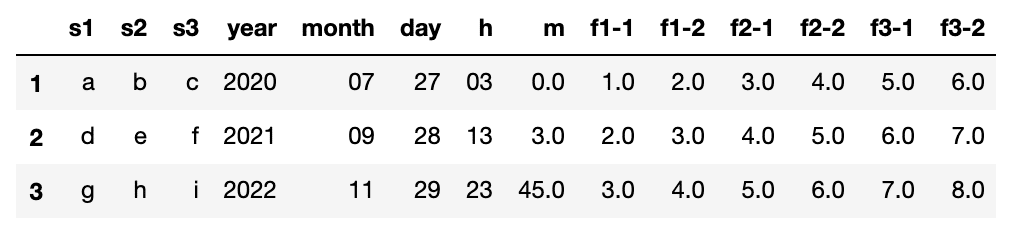
All done!
Reference site. Thank you.
https://stackoverflow.com/questions/26551662/import-text-to-pandas-with-multiple-delimiters
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_csv.html?highlight=delimiter%20csv
Environment
Python; 3.7.2
pandas; 1.0.5
ちょっと広告です
https://business.xserver.ne.jp/
https://www.xdomain.ne.jp/
★LOLIPOP★
.tokyo
MuuMuu Domain!