pandasでcsvを複数の区切り文字で区切って読み込むの巻

はじめに
pandasのread_csvにてcsvファイルを読み込むときに、複数の区切り文字(delimiter)で区切って読み込むための指定方法がわかんなくて調べたのときのメモです。
sep(またはdelimiter)にて区切り文字を指定するときに “[]” に区切り文字を詰め込む
で、よいと。
タイトルママなので早速やってみます。
やりかた
次のようなcsvファイル(tempo.csv)があり、いくつかの区切りとなる文字にて区切って読み込みたいとします(時刻の右側はtab区切りがあります)。
s1,s2;s3,datetime f1,f2,f3 a,b;c,2020/07/27 03:00 1.2,3.4,5.6 d,e;f,2021/09/28 13:03 2.3,4.5,6.7 g,h;i,2022/11/29 23:45 3.4,5.6,7.8
ここでは
“,”、”;”、”/”、” “(スペース)、”:”、”\t”(tab)、”.”
の7種を区切り文字として使用し区切ってみます。
sep(またはdelimiter)にて区切り文字を指定するときに、
sep = “[]”
として[]内に複数の区切り文字を記述すればよくて。。。
なお、そのときに、engine=’python’を指定しておきます。
# pandasをpdとして読み込む
import pandas as pd
#sep(またはdelimiter)で区切り文字(delimiter)を指定するとき、"[]"にて複数の区切り文字を記述できる。
#その際engine='python'を指定
df = pd.read_csv("tempo.csv", sep = "[,;/ :\t.]", engine='python')
df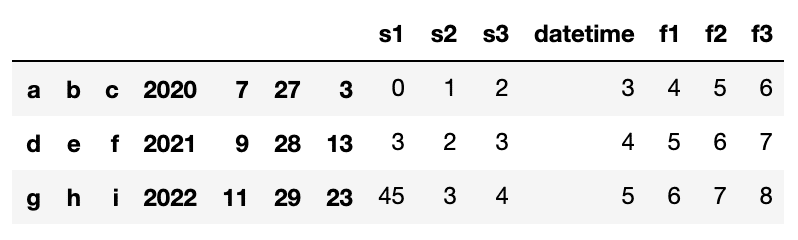
でけた。
ちなみに、何も指定せずに読み込むと、defaultの区切り文字は
“,”
なので、
# pandasをpdとして読み込む
import pandas as pd
#defaultの区切り文字は","
df = pd.read_csv("tempo.csv")
df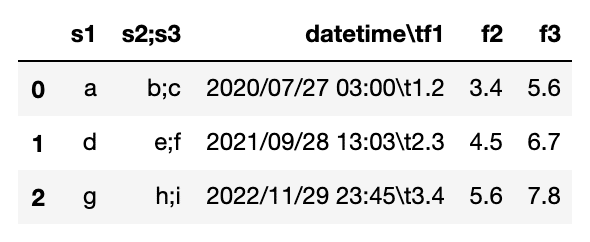
となります。
おまけ;headerを整える
区切ってしまうと、元々あったheaderでは新たに生じた列の項目名が足りなくなってずれまくります。指定した覚えがないのに勝手にindexになってるし。。。
なので、新たに生成するtableの列数に合わせたカラム名のリストを作っておいて、差し替えてやることにします。
# pandasをpdとして読み込む
import pandas as pd
#あらかじめcolmumn名のリストを作成しておく
cols = ["s1","s2","s3","year","month","day","h","m","f1-1","f1-2","f2-1","f2-2","f3-1","f3-2"]
#読み込む時にnamesで先程のcolumn名のリストを指定
df = pd.read_csv("tempo.csv", sep = "[,;/ :\t.]", engine='python', names = cols)
#dropで元々のheaderは除去
df.drop(df.index[0], inplace = True)
df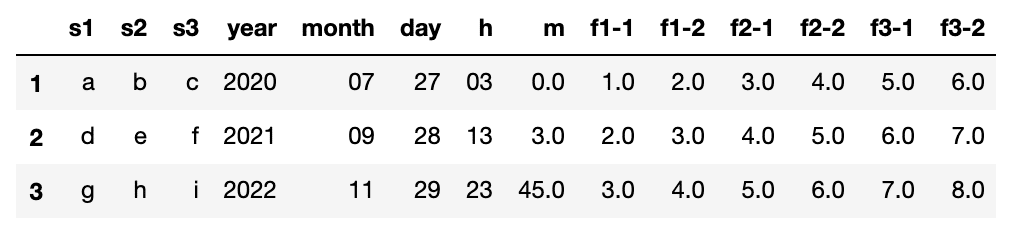
これでよしと。
ちょっと広告です
https://business.xserver.ne.jp/
https://www.xdomain.ne.jp/
★LOLIPOP★
.tokyo
MuuMuu Domain!
参考にしたサイト。ありがとうございます。
https://stackoverflow.com/questions/26551662/import-text-to-pandas-with-multiple-delimiters
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_csv.html?highlight=delimiter%20csv
環境
この記事の内容は
Python; 3.7.2
pandas; 1.0.5
にて実施しました。
このブログはエックスサーバー
WordPressを使うならロリポップ!
簡単インストール完備で楽々スタート!
世界にたった一つ、あなただけのドメインを登録しよう!
格安ドメイン取得サービス─ムームードメイン─